Come funziona Git
Introduzione: tipi di sistema di controllo delle versioni

Che cos'è Git
Git è un Version Control System (VCS), un sistema di controllo delle versioni. Un VCS è fondamentalmente un software progettato per registrare le modifiche apportate a uno o più file nel corso del tempo, e permette di annullare o di cancellare tutte le modifiche apportate o in sospeso in uno o più file.
Se stiamo lavorando a un progetto con molti file, il VCS permette di controllare l'intero progetto. Questo vuol dire che, se è necessario, grazie al VCS è possibile ripristinare uno o più file in una qualsiasi delle loro versioni precedenti ovvero riportare l'intero progetto a una versione precedente.
Un'altra qualità molto importante di un VCS è che permette anche di confrontare le modifiche apportate a un file tra due versioni, per vedere esattamente cosa è stato modificato in ogni file, quando è stato modificato e chi ha apportato la modifica. Grazie ai commenti è possibile anche vedere perché è stata fatta una modifica.
Attenzione, qui stiamo parlando di file in senso ampio e non solo di quelli che contengono del codice, perché in realtà Git è un sistema universale che può essere usato per il controllo di versione di tutti i tipi di documenti, prodotti da qualsiasi applicazione, immagini incluse.
Tipi di VCS
Per capire come funziona Git è necessario prima capire due cose. Una è che Git non è l'unico VCS esistente. L'altra è che Git è solo uno specifico tipo di VCS.
Esistono infatti tre tipologie diverse di VCS:
- Sistemi di controllo della versione locali
- Sistemi di controllo della versione centralizzati
- Sistemi di controllo della versione distribuiti
Sistemi di controllo della versione locali
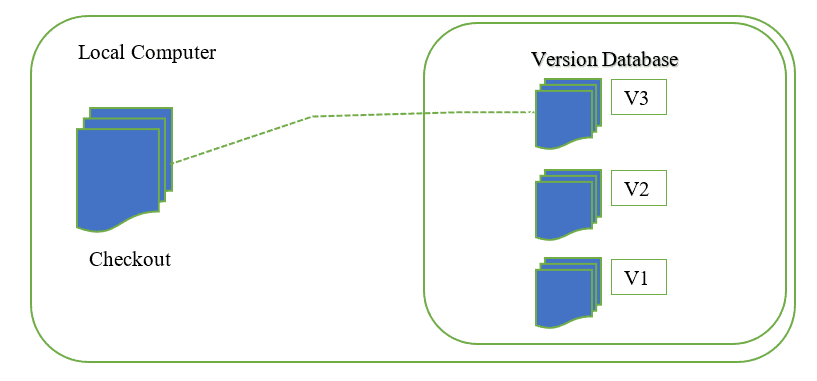
I Sistemi di controllo della versione locali, o Local Version Control Systems, sono dei software che utilizzano un database locale che risiede sul computer locale.
La loro struttura è molto semplice. Nel database locale ogni modifica di un file viene memorizzata come una patch. Ogni patch contiene solo le modifiche apportate al file dalla sua ultima versione. Per vedere l'aspetto del file in un determinato momento, è necessario sommare tutte le patch apportate al file fino a quel momento.
Questo sistema non è perfetto. Il problema principale è che tutto viene memorizzato localmente. Se dovesse accadere qualcosa al database locale, tutte le patch andrebbero perse. Se dovesse accadere qualcosa a una singola versione del file, tutte le modifiche successive a quella versione andrebbero perse.
Inoltre, collaborare con altre persone o con il proprio team sugli stessi file è molto difficile o quasi impossibile.
Sistemi di controllo della versione centralizzati
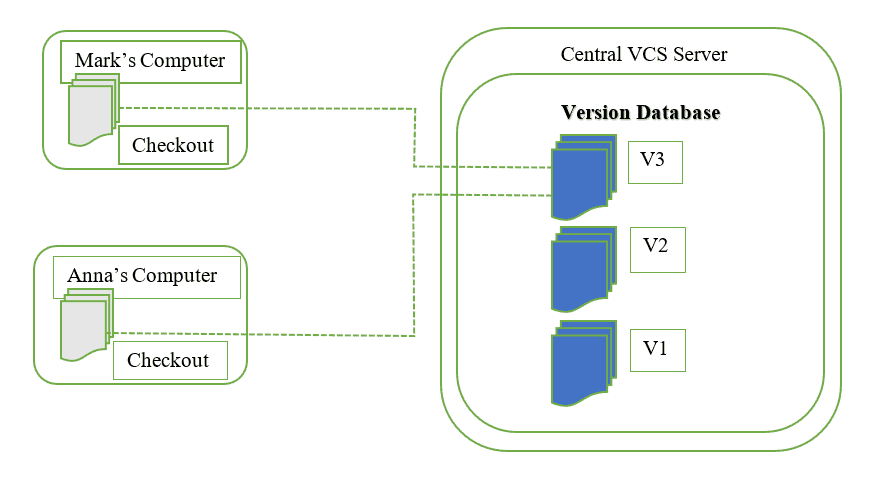
I Sistemi di controllo della versione centralizzati, o Centralized Version Control Systems, utilizzano un unico server che contiene tutte le versioni dei file. Questo consente a più client di accedere simultaneamente ai file sul server, di trasferirli sul proprio computer locale o di inviarli al server dal proprio computer locale.
In questo modo, di solito tutti sanno cosa stanno facendo gli altri partecipanti al progetto. Gli amministratori hanno il controllo su chi può fare cosa. Tutto questo consente una collaborazione molto più facile con altre persone o con il proprio team.
Il problema principale di questa struttura è che tutto viene memorizzato sul server centralizzato. Se dovesse accadere qualcosa a quel server, nessuno potrebbe salvare le proprie modifiche di versione, estrarre i file o collaborare. Come nel caso del controllo di versione locale, se il database centrale si corrompe e non vengono conservati i backup si perde l'intera storia del progetto, tranne le singole istantanee che le persone hanno sulle loro macchine locali.
Gli esempi più noti di sistemi di controllo di versione centralizzati sono Microsoft Team Foundation Server (TFS) e SVN.
Sistemi di controllo della versione distribuiti
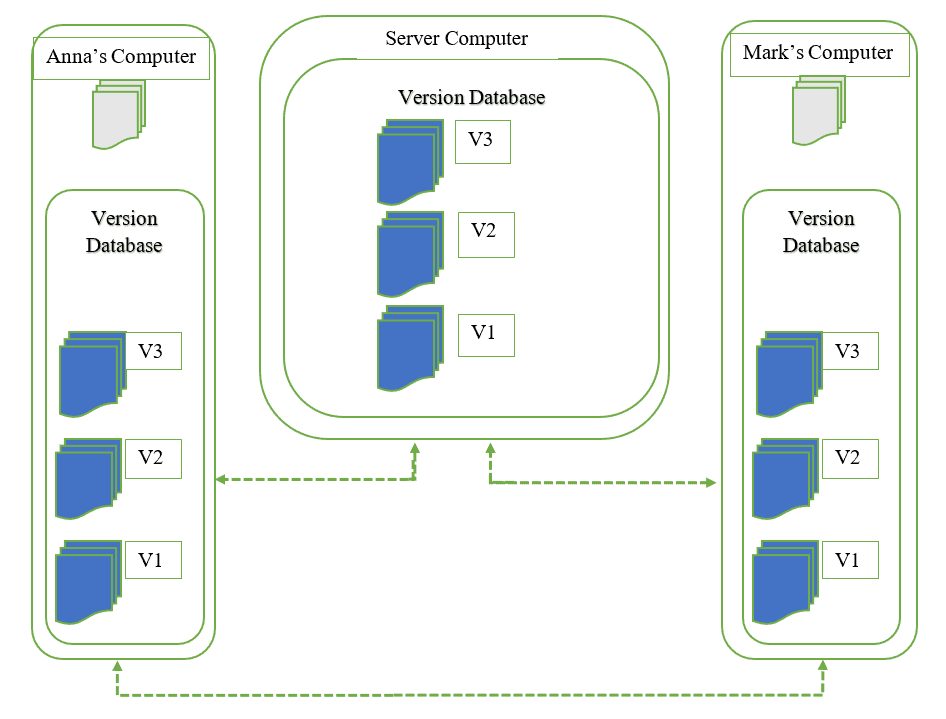
I Sistemi di controllo della versione distribuiti, o Distributed Version Control Systems, i client non si limitano a controllare l'ultima istantanea dei file dal server, ma eseguono il mirroring completo del repository, compresa la sua storia completa. In questo modo, tutti coloro che collaborano a un progetto possiedono una copia locale dell'intero progetto, cioè possiedono il proprio database locale con la propria storia completa.
Con questo modello, se il server diventa indisponibile o addirittura perde tutti i dati, uno qualsiasi dei repository client può inviare una copia della versione del progetto a qualsiasi altro client o sincronizzarsi con il server quando sarà disponibile. È sufficiente che un client contenga una copia corretta che può quindi essere facilmente ridistribuita.
L'esempio più noto di sistema di controllo di versione distribuito è Git.
Come funziona Git
Per capire come funziona Git, è necessario prima capire come Git salva i dati relativi alle modifiche apportate a uno o più file.
Salvare le modifiche con gli altri VCS
Altri sistemi di controllo delle versioni tengono traccia delle modifiche apportate a un file e le salvano. Alla fine abbiamo un file di base e un elenco di modifiche apportate a quel file nel corso del tempo. Quindi, a ogni versione (ogni commit genera una nuova versione), vediamo solo le modifiche apportate a un particolare file in quella versione.
Questo modo di salvare le modifiche rende più difficile vedere lo stato dell'intero progetto, soprattutto per i file ai quali non sono state apportate modifiche in una particolare versione.
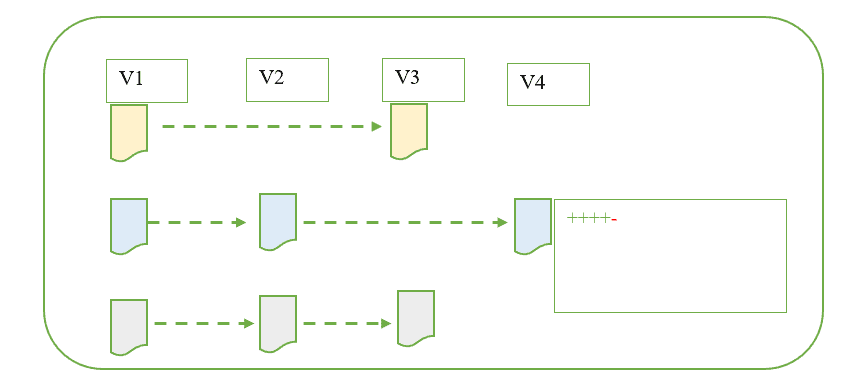
Cosa fa Git
In Git il modo con il quale si salvano e si pensa ai dati è leggermente diverso. Git vede i suoi dati più come una serie di "istantanee nel tempo" prese dall'intero progetto. Ogni volta che viene effettuato un "commit" o salvato il progetto, Git genera un'istantanea del progetto in quel momento, compresi tutti i file presenti in quel momento e salva un riferimento a quella istantanea.
In questo modo tanto per cominciare è possibile richiamare qualsiasi istantanea fatta in un determinato momento e vedere lo stato dell'intero progetto con tutti i suoi file in quel momento. Questo differisce dagli altri tipi di VCS, in cui si guardano le versioni passate e si vededono solo le modifiche apportate ai file che sono stati cambiati. Invece, nel caso di Git, ogni snapshot contiene tutti i file del progetto.
La cosa che Git fa in modo speciale è il modo in cui gestisce i file che non sono stati modificati in una particolare istantanea. Li salva, ma è abbastanza efficiente da non salvare una copia fisica di ogni file che risulta invariato in un'istantanea. Invece, crea un link all'ultima versione di ciascuno dei file invariati.
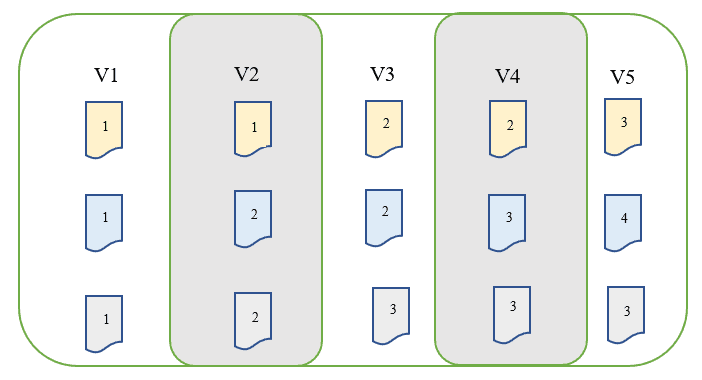
Funzioni di Git a livello locale
Un altro dei vantaggi di Git è che tutto funziona a livello locale. Essendo Git un sistema di controllo di versione distribuito, tutte le modifiche vengono salvate localmente su ogni macchina. Possono poi essere sincronizzate con il server o estratte da esso.
Quando si prende ("pull") una nuova versione dal server, si prende anche l'intera cronologia delle modifiche. La macchina locale che le riceve ha la storia completa delle modifiche apportate a tutto il progetto. Per questo tutte le operazioni di Git in locale sono veloci, quasi istantanee: vengono lette dal database locale.
Per esempio, se si desidera vedere le modifiche apportate al progetto qualche settimana o qualche mese prima, Git confronta il repository locale con i dati del repository remoto e prende ("pull") solo i file che sono stati modificati. È possibile utilizzare Git senza alcun accesso alla rete. Le modifiche vengono poi caricate quando si raggiunge una rete.
Tracciamento delle modifiche
Un altro aspetto molto importante di Git è il modo in cui le modifiche vengono salvate nel progetto. Prima che qualsiasi cosa venga salvata nel database, riceve una checksum. Tutto quello che Git salva nel suo database lo salva non per nome di file ma per valore di hash del suo contenuto. Quando si cerca un particolare commit, Git usa il suo checksum per trovarlo.
Git utilizza la funzione di hash crittografico SH1 per generare i checksum. SHA1 genera una stringa di 40 caratteri composta da caratteri esadecimali e calcolata in base al contenuto dei dati inseriti. Inoltre, l'algoritmo di SHA1 è fatto in maniera tale per cui solo gli stessi dati in ingresso possono produrre lo stesso identico hash. Anche la più piccola modifica dei dati di input genererà un hash diverso.
La scrittura del riferimento a un commit sotto forma di checksum (la "somma di controllo") consente a Git di mantenere l'integrità dei dati. Trattandosi di un sistema di controllo di versione distribuito, bisogna essere certi che ogni file sia unico e che due persone stiano guardando esattamente lo stesso file. Quando Git confronta due file, ne confronta le checksum. Anche la più piccola modifica a uno qualsiasi dei file del progetto cambia l'intera somma di controllo del progetto per un determinato commit.
Invece, altri sistemi di controllo della versione usano semplici segni di riferimento per le checksum, come V00234, V00235 e così via. Utilizzando la funzione di hash crittografico SH1 il rischio di una collisione, cioè di avere due hash con lo stesso valore, è nullo.
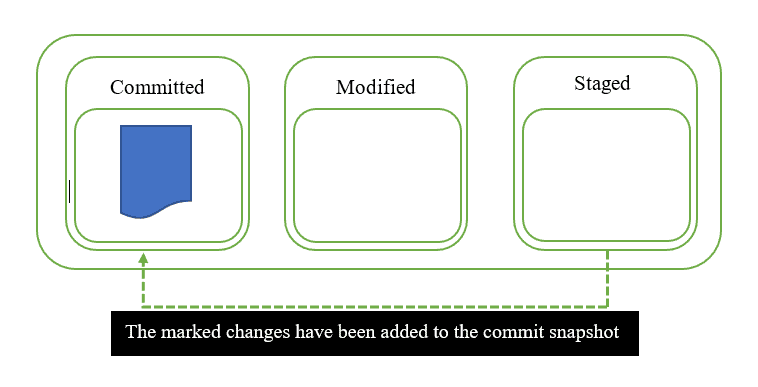
I tre stati di Git e le tre sezioni di un progetto Git
Un aspetto che spesso confonde chi inizia a utilizzare Git è la nomenclatura degli stati dei file. In realtà, se si capisce il motivo e la logica per cui sono stati scelti, diventa abbastanza semplice orientarsi.
I tre stati di Git
Git prevede tre stati principali in cui possono risiedere i file:
- Committed (impegnato)
- Modified (modificato)
- Staged (allestito)
Questi tre stati costituiscono un sistema basato sulla promozione. Ogni file può risiedere in uno di questi tre stati e cambiare stato, cioè essere promosso, a seconda di ciò che è stato fatto.
Committed
Questo stato indica che il file è memorizzato in modo sicuro nel database locale.
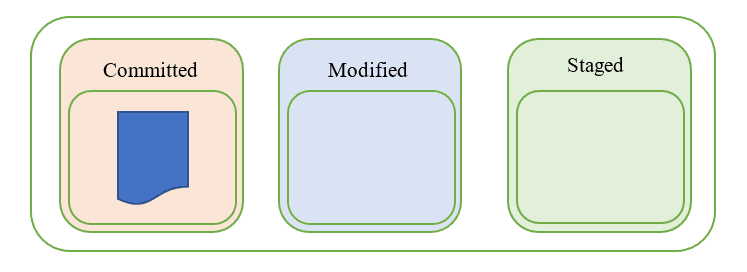
Modified
Quando viene fatta una modifica a un file, lo stato del file passa da "committed" a "modified", cioè da "impegnato" a "modificato". Questo significa che il documento è cambiato rispetto all'ultima versione, che era "committed" in quanto salvata nel database locale. Possiamo vedere lo stato "modified" come una dichiarazione: “stiamo lavorando su questo file, ci potranno essere ancora altre modifiche”.
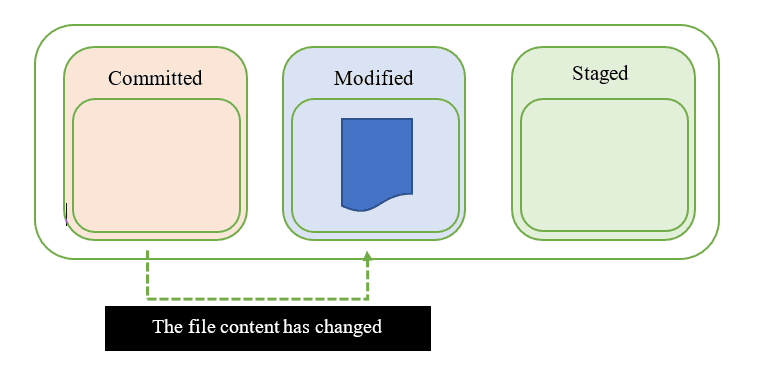
Staged
Quando sono finito tutte le modifiche al file, questo passa allo stato "staged", cioè il file è "allestito", nel senso che ora è pronto per essere aggiunto al database git locale. Quindi, è stato contrassegnato per essere inserito nella prossima istantanea di "commit".
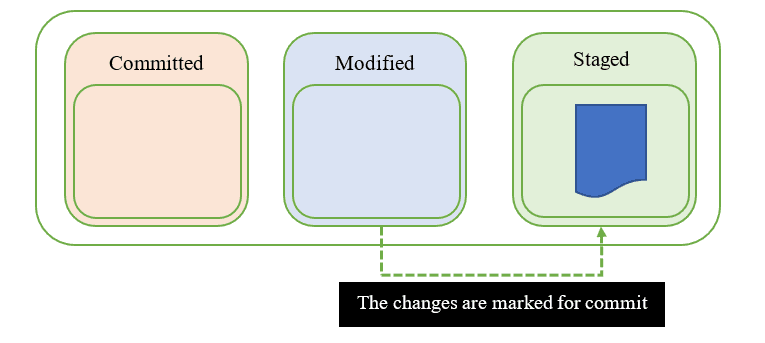
È importante notare che questi tre stati dei file si riferiscono solo ai file tracciati in un progetto Git. Un file può essere contenuto all'interno di un progetto senza che le sue modifiche siano tracciate da Git. Quando si iniziano a tracciare le modifiche in Git per un file che non è stato tracciato precedentemente, questo passa automaticamente allo stato di "Staged".
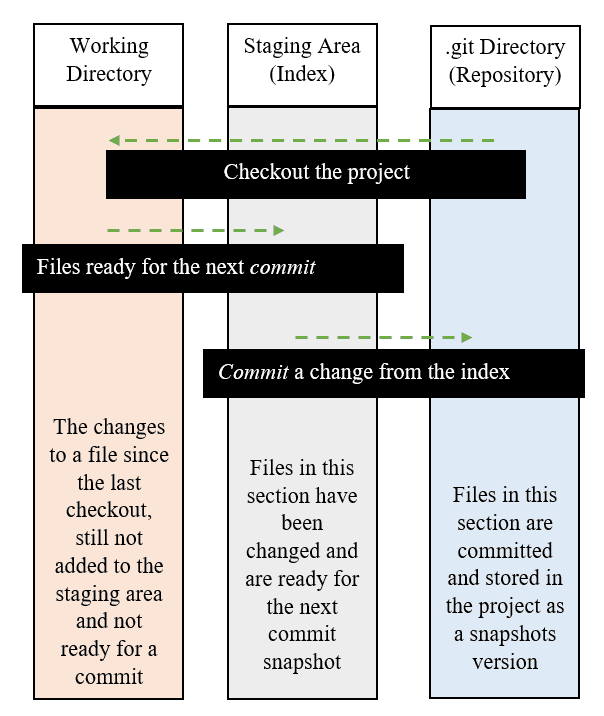
Tre sezioni di un progetto Git
In maniera simile a come i file possono essere in tre stati diversi, così un progetto Git è composto da tre sezioni diverse.
La prima sezione è la cartella ".git", nota anche come "repository". È qui che Git memorizza i metadati e il database degli oggetti del progetto.
La sezione successiva è la directory di lavoro o "working directory". Si tratta di un singolo checkout, o punto di controllo in uscita, di una versione del progetto. In pratica, qui si possono modificare i file del progetto.
La terza sezione è l'"area di Staging", nota anche come "indice". È l'area compresa tra la directory di lavoro e la directory .git. Qui sono memorizzati tutti i file pronti per il "Commit".
Quando si esegue il "Commit", ciò che si trova nella "area di staging" si sposta nella nuova versione del repository, escludendo tutto quello che si trova nella directory di lavoro.
In questo modo è possibile modificare i file a piacimento, ma solo ciò che viene spostato nell'area di "Staging" sarà oggetto di "Commit". Tutto ciò che viene modificato ma che non viene inserito in un repository rimane nella directory di lavoro.
Git Merge vs. Git Rebase
Quali sono le differenze tra queste due azioni in Git? Quando si deve usare il "merge" (unione), quando il "rebase" (ribasamento) e perché?
Per capirlo dobbiamo prima capire a cosa servono. Per farlo, ricapitoliamo lo scopo di Git, che è un software molto efficace perché estremamente pragmatico.
Git è un sistema di controllo delle versioni che viene usato per memorizzare e salvare le modifiche apportate a uno o più file nel corso del tempo. È un ottimo strumento perché mostra lo stato di un file in qualsiasi momento specifico della storia e mostra informazioni precise su chi ha cambiato cosa in quale momento. Tuttavia non è sempre così semplice lavorare con queste informazioni se ci sono molti dati e molti creatori.
Per questo Git offre la possibilità di lavorare in parallelo con altri utenti e di avere un sistema di monitoraggio in tempo reale delle modifiche ai file. È un modo molto pratico, tuttavia può essere un problema quando vogliamo salvare tutte le modifiche fatte da persone diverse in gurppi diversi e fonderle nel file finale. Per poter compierer questa azione con Git abbiamo due funzioni diverse: "merge" e "rebase".
La differenza principale tra di esse può essere osservata dai diagrammi illustrati di seguito.
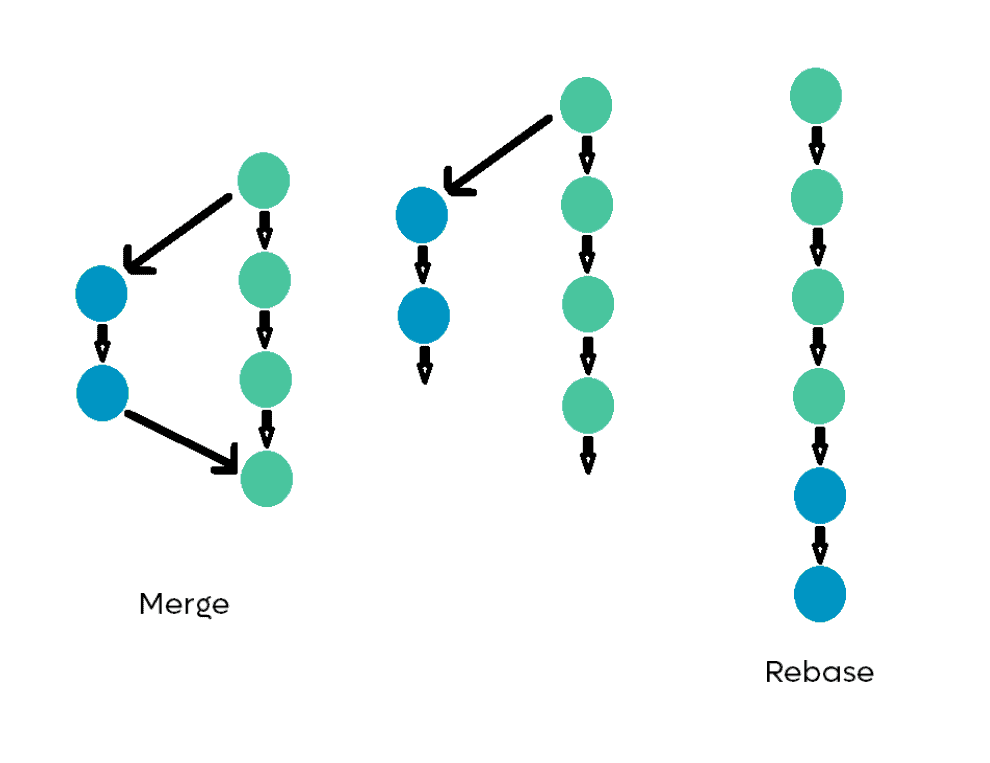
Cosa ci mostra l'immagine?
Nel diagramma centrale sono presenti due "branch" o rami. Il verde rappresenta il ramo master e il blu rappresenta un nuovo ramo creato a partire dal master. Per ogni "branch", abbiamo un paio di commit indipendenti.
Nel diagramma di sinistra, uniamo un nuovo ramo al master con l'azione "merge". L'azione "merge" assomiglia a un nuovo "commit", in cui possiamo visualizzare tutte le modifiche create in quel ramo separato. Dopo la fusione possiamo anche vedere storicamente quale ramo fa parte di quale "commit". L'azione "merge" memorizza tutte le modifiche così come sono avvenute, rappresentando la storia reale sia del master che del branch.
Nel diagramma di destra, viene invece usata l'azione "rebase". Questa azione ha inserito tutti i commit del nuovo ramo nel ramo master. Questa non è la storia reale, perché è stata forzata da "rebase".
Perché usare rebase?
Quando si lavora su un progetto più grande, si può pensare di avere molti "branch" o rami. L'uso delle azioni di "merge" permette la vista di tutti i vecchi rami uniti, il che porta a un certo disordine all'interno di un progetto molto grande. È difficile seguire quale commit proviene da quale ramo.
"Rebase" ha una cronologia più pulita, ma solo apparentemente, perché i commit di git sono immutabili. Utilizzando "rebase", Git crea nuovi commit e li colloca nel ramo master, alla sua base. Per questo si dice che si sta facendo un "rebase", in italiano una "ribasatura", cioè l'azione che indica che si sta ripristinando la base di appoggio di una struttura.
I commit nei rami separati rimangono invece al loro posto, e quindi vengono cancellati automaticamente, man mano che diventano irraggiungibili perché il ramo a cui appartengono non c'è più. Alla fine di questo processo, la cronologia appare più pulita.
E i conflitti?
L'uso di entrambe le azioni può richiedere la risoluzione di alcuni conflitti. Questi conflitti si verificano quando ci sono cambiamenti nei contenuti degli stessi file in rami diversi. Quindi, mentre viene fatto il "merge" o il "rebase", è necessario risolvere i conflitti presentati decidendo quale parte del contenuto è corretto e da quale ramo proviene. Questo problema viene risolto allo stesso modo in entrambe le azioni.
Cosa usare?
In caso di dubbio, l'uso di "merge" è sempre l'opzione migliore. Il "rebase" è consigliato solo se i "commit" sono memorizzati localmente. Quando il lavoro è online, possono nacere dei problemi per gli altri membri del team. Uno di questi problemi, ad esempio, è la perdita completa del loro lavoro salvato.

In futuro
(forse)
- Workflow di base in Git: add, commit, push, pull.
- Creazione e gestione dei branch.
- Collaborazione con Git: fork, pull requests, code review.
- Git hosting: GitHub, GitLab, Bitbucket.
- Git GUI vs. Git CLI.
- Best practices per l'uso di Git in team.
- Git hooks e automazione.
- Git per la gestione di documenti non di codice.
- Risoluzione dei conflitti in dettaglio.
- Git stash e altri comandi avanzati, bare repository.